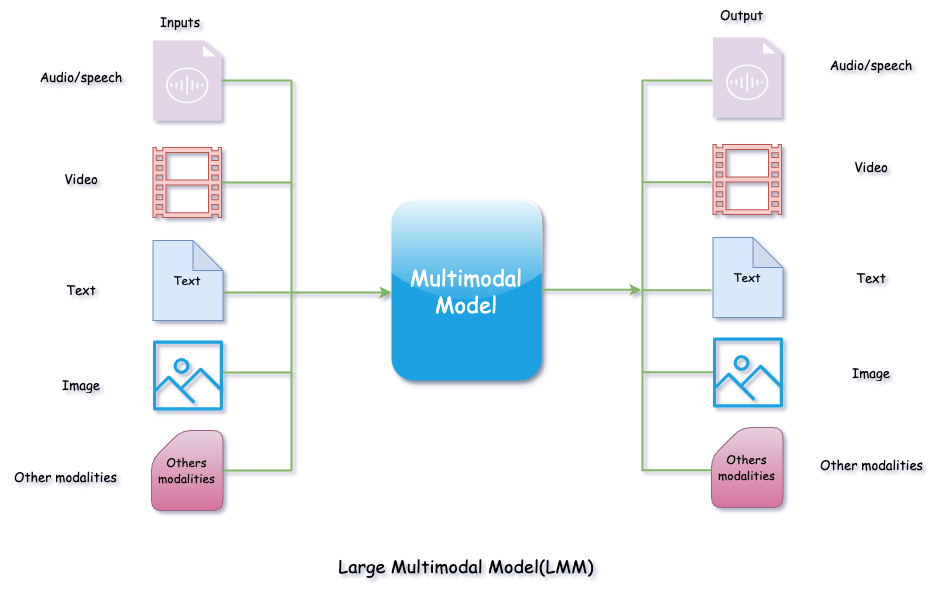
In this post, I will briefly define Large Multimodal Models (LMM), explain the data modalities of LMMs, and demonstrate Google Gemini’s multimodal capabilities using text and images. This is purely a no-code blog post. I will demonstrate everything directly from the Google Cloud Console using Vertex AI Studio and Vertex AI to showcase a simple example of using multimodal inputs (text file and image)
Introduction
A Large Multimodal Model (LMM) is an Artificial Intelligence (AI) model capable of processing and understanding multiple types of input data modalities simultaneously and providing outputs based on this information. The input data can include a mix of audio, video, text, images, and even code.
Data modalities of LMM
Audio
The model can understand sound, music, spoken language, and any other form of auditory inputs.
Images
The model can understand objects, scenes, text, and even emotions from an image.
Video
The model can understand visual and auditory elements form the video. It’s a combination of audio and visual data
Text
Text includes any form of content such as books, PDF files, text files, online news, articles, research papers, social media posts, and so on. The model understands the textual context, processes it, and generates outputs.
Code
The model also takes programming language code as input.
Multimodal examples
Multimodal means one or more of the following:
Input and output are of different modalities
Can take one type of input modality and generate one type of modality output (example: text-to-image, image-to-text, audio-to-text). Here is the example diagram:

Inputs are multimodal
Can take more than one type of inputs and generate one type output. Here is the example diagram:
 In above, diagram we can see that LMM is taking three types of modalities (Audio, text and image) and generating one modality output (video)
In above, diagram we can see that LMM is taking three types of modalities (Audio, text and image) and generating one modality output (video)
Outputs are multimodal
Can take one type of input and generate more than one output. Here is the example diagram:
 In above, diagram we can see that LMM is taking one type of modality (video) and generating three types of output (audio, text, and video)
In above, diagram we can see that LMM is taking one type of modality (video) and generating three types of output (audio, text, and video)
Inputs and Outputs are multimodal
Can take more than one of inputs and generate more than one output. Here is the example diagram:

In above, diagram we can see that LMM is taking more than one types of modalities (audio, video, image, text and code) and generating more than one types of output modalities (audio, video, image, text and code)
Large Multimodal Model(LMM) Prompting With Google Gemini
I will show you the steps to use the Goolge Gemini multimodal.
1. Login to Google Cloud
Since I am demonstrating from the Google Cloud Console, you will need to login to your Google Cloud account or need to signup if you don’t Google Cloud account. here is the link cloud.google.com. For this demonstration I have set up a branch new account.
2. Setup Billing
If you haven’t set up billing, you’ll need to add your payment details so Google can charge you accordingly. If you’re a new user on the Google Cloud Platform, you’ll get a 90-day free trial with $300 USD in credit, which will be more than enough to try out Gemini for our demonstration.
3. Create Project
Go to your Google Cloud Console https://console.cloud.google.com and then create new google project clicking one red box 1 which will open red box popup and click on red box 2.

Give the name to the Google project form red box 3.
You can also see the project ID just below the project name text box; this ID cannot be changed in the future. You can leave the location set to the default.
 .
After you hit a save button it will take few seconds to create a project.
.
After you hit a save button it will take few seconds to create a project.
4. Enable APIs & Services
To enable APIs & Services first you need to go to red box 4 and click on red box 5
 Now you are inside a project dashboard. Search for “Enable APIs & Services” form search text box (Red box 6) and click on Enable APIs & Services (Red box 7)
Now you are inside a project dashboard. Search for “Enable APIs & Services” form search text box (Red box 6) and click on Enable APIs & Services (Red box 7)
 Click on + ENABLE APIS AND SERVICES (Red Box 8)
Click on + ENABLE APIS AND SERVICES (Red Box 8)
 Search for
Search for Vertex AI API and click on Vertex AI API (Red Box 9)
 Click on
Click on Vertex AI API text (Red Box 10)
 Click on enable button (Red Box 11) You may be asked for billing information if you haven’t submitted it already.
Click on enable button (Red Box 11) You may be asked for billing information if you haven’t submitted it already.
 It will take coupe of seconds to enable the
It will take coupe of seconds to enable the Vertex AI API.
Once the Vertex API is enabled, your browser window will display the screen shown below.

5. Prompting With Multimodal
Now let’s go to the Vertex AI studio.
Search for Vertex AI and click on Vertex AI (Red Box 12).
 Next step is to clink on
Next step is to clink on freeform menu (Red Box 13)
 From the screen above, you can choose the LMM model (Red Box 14), upload files (Red Box 15) and input prompts.
From the screen above, you can choose the LMM model (Red Box 14), upload files (Red Box 15) and input prompts.
Example
I have below text prompt and multimodal inputs (a text file knowledge-base.txt and an image mount-everest.png).
Text prompt is :
Read the information from both the text file and the image. Tell us the old and new heights
Image is : (mount-everest.png) Image has text on it.

Text file is (knowledge-base.txt): text file has below content
| |
Let me try with only text prompt, what will be the output?

Look at the response. Model did not find the information that we asked for.
Output is:
Please provide me with the text file and the image so I can read the information and tell you the old and new heights.
Let’s try with the files (knowledge-base.txt text file and mount-everest.png image file) and supply same prompt used before.

Now, look at the output.
The model is reading both the knowledge-base.txt text file and the mount-everest.png image file, and is responding the correct result.
Output is:
The old height of Mount Everest was 8,848 meters. The new height of Mount Everest is 8,849 meters.
Old height of Mount Everest was read from knowledge-base.txt text file and new height from the mount-everest.png image file, which is the expected output.
Congratulations! You have successfully learned how to use Large Multimodal Model (LMM) prompting with Google Gemini and Vertex AI
One more thing: after completing the lab, don’t forget to delete your project; otherwise, Google may charge you.
In this post, we explored the capabilities of Large Multimodal Models (LMM) and demonstrated how Google Gemini processes different data modalities to generate meaningful outputs. By using text and image inputs, we saw how the model effectively interprets and combines multimodal data to provide accurate results
Recorded YouTube video for the demonstration: