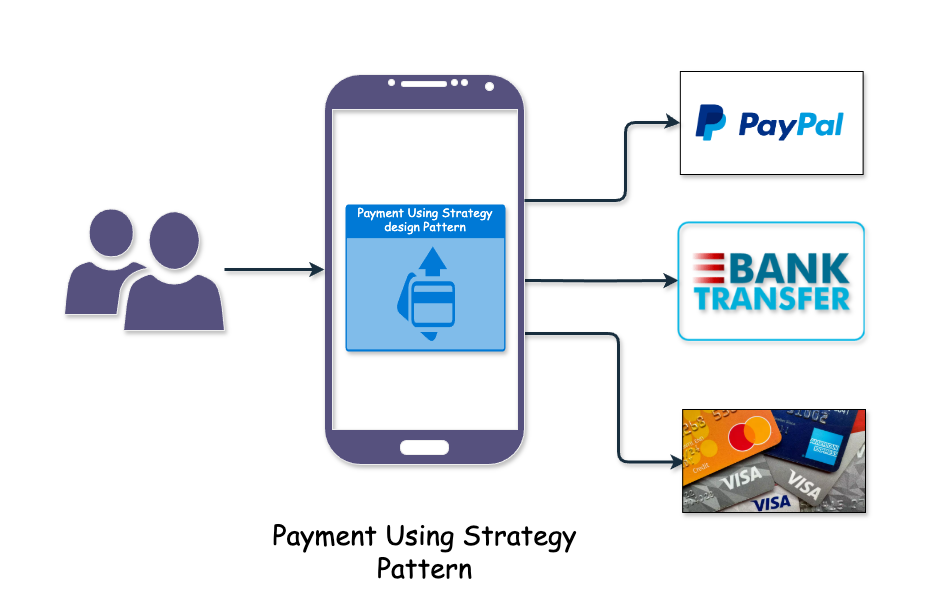
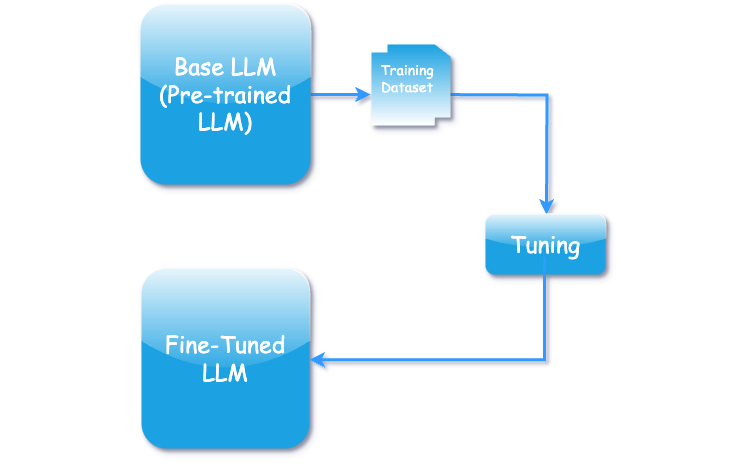
I am a Software Engineer with a passion for lifelong learning, problem-solving, and always improving oneself 📚
I help caring software crafters achieve technical excellence by using the best software engineering practices.
I have a solid background in using language-agnostic engineering practices such as Extreme Programming, peer programming, domain driven design and clean code.
Over the last decade, I successfully applied these practices in many kinds of industries such as E-commerce, logistics, warehousing systems, ICT Projects, content sharing etc. 💪
Beyond software engineering, I love reading books, and travelling. And occasionally writing the blog posts 😊.